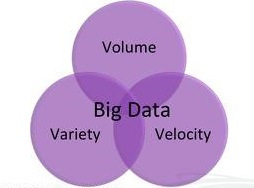
El concepto de Big Data es, cuando menos, bastante "abstracto" de ahí que el analista Doug Laney (actualmente en Gartner) ya hace bastantes años (en 2001) decidiese hacerlo más accesible con la idea de las 3 "V": Volumen, Variedad y Velocidad.
El concepto de Big Data es, cuando menos, bastante "abstracto" de ahí que el analista Doug Laney (actualmente en Gartner) ya hace bastantes años (en 2001) decidiese hacerlo más accesible con la idea de las 3 "V": Volumen, Variedad y Velocidad.Volumen
En principio es lo que más atrae del Big Data: la posibilidad de procesar enormes cantidades de datos.
Además es indiscutible que de cara al análisis del información es mejor tener una gran cantidad de datos que un buen modelo que lo analice, cuanto más te acerques al concepto estadístico de "universo" menos sentido tiene trabajar con "muestras" haciendo inferencias y es precisamente eso lo que permite el Big Data.
Imaginemos que queremos predecir la demanda de un producto de nuestra portfolio, si lo hacemos teniendo en cuenta 5 factores, ¿tendremos más éxito que si lo hacemos teniendo en cuenta 200?
Hasta hace poco muchas empresas tenían grandes cantidades de datos almacenados pero no podían explotarlos, pero con el Big Data se abre una oportunidad para conseguirlo si bien hay que tener en cuenta las infraestructuras necesarias.
Asumiendo que el volumen de datos a utilizar supera las capacidades de las bases de datos relacionales más convencionales (lo cual ya es mucho para buena parte de las organizaciones) entonces básicamente tenemos dos opciones en términos de procesamiento:
- Arquitecturas de procesamiento masivo en paralelo, como bases de datos y data warehouses del estilo de Greenplum (Pivotal).
- Soluciones basadas en Apache Hadoop.
Lo más habitual es que un data warehouse implique esquemas predeterminados, que cuesta tiempo evolucionar, sin embargo, Apache Hadoop no obliga a ninguna condición predeterminada de los datos a procesar.
Hadoop es básicamente una plataforma para se usa para distribuir un determinado problema de procesamiento de datos entre un cierto número de servidores, facilmente cientos o incluso miles.
Los orígenes de Hadoop están en Yahoo! que lo desarrolló como una solución Open Source basándose en los trabajos pioneros de Google para la compilación de búsquedas indexadas con su framework (modelo de programación) MapReduce.
A ver si no me lio ya que no soy un experto en la materia, simplemente intento aprender y compartir, lo que hace el MapReduce de Hadoop se divide en dos partes:
- La parte "Map" se ocupa de la distribución de los set de datos entre múltiples servidores y de la operación de esos datos.
- La parte "Reduce" recombina los resultados obtenidos.
Para almacenar datos Hadoop utiliza su propio sistema de ficheros distribuidos (HDFS), así que lo que sucede es que 1º) se cargan los datos en HDFS, 2º) MapReduce opera los datos y 3º) el output se obtiene vía HDFS.
Es claramente un proceso batch y, por lo tanto, Hadoop no es ni una base de datos ni un data warehouse sino un apoyo analítico a los mismos.
Y no hay que olvidar que trabajar con Hadoop es todo menos fácil, se necesita de personal muy formado y experimentado, y esto no es barato.
Os dejo el vídeo de un webinar sobre Hadoop y además ¡en español!:
El ejemplo paradigmático sería Facebook, esta red social usa como base de datos MySQL de donde se toman los datos que van a Hadoop que los procesa para obtener por ejemplo las recomendaciones que facebook te ofrece en base a los intereses de tus amigos.
Velocidad
La importancia de la velocidad de los datos, el ritmo al que los datos fluyen en la organización (son generados, capturados y compartidos), ha evolucionado de un modo parecido a lo que ha sucedido con el volumen de datos.
No voy a ponerme demasiado filosófico, pero es indiscutible el hecho de que Internet y las comunicaciones móviles generan cantidades ingentes de datos (vale, no hablaré de zetabytes) pero la cuestión es que las organizaciones no se pueden permitir tomar decisiones sin tener en cuenta el factor tiempo.
No todo es procesar gigantescas cantidades de información sino que también hay que conseguir un feedback y en ocasiones tiene que hacerse en "tiempo real" y para ello se utilizan tecnologías de streaming de datos.
Basta con pensar en las necesidades asociadas al uso de aplicaciones para smartphones o al juego on-line, esta claro que cuanto más veloz sea el feedback mayor será la ventaja competitiva.
En esta "v" tenemos por un lado a IBM con su InfoSphere Streams y por otro a los chicos del Open Source con sus soluciones bastante menos pulidas como son los frameworks de Twitter (Storm) y de Yahoo! (S4).
Variedad
Hay que reconocer que es raro que los datos se nos presenten siempre de una forma clara y ordenada bien lista para su procesamiento, es un lugar común en el Big Data el hecho de que los datos vengan de fuentes muy diversas y que no entren dentro de la tipología que exigen los esquemas relacionales.
Estamos hablando de texto en redes sociales, imagenes, vídeo, audio o datos de sensores en bruto, nada de esto está preparado para la típica integración de datos en una aplicación.
Nos adentramos pues en la bifurcación más importante en la tipología de los datos: estructurados y no estructurados, este asunto lo trataremos independiente en el próximo post.
Un uso habitual del Big Data es tomar datos no estructurados para extraer significado de los mismos, bien para el consumo por parte de personas bien como input para aplicaciones, la cuestión aquí es que cuando se pasa de datos en bruto a datos estructurados ya procesados hay mucha información que se pierde (y ya no se puede recuperar) de ahí un "refrán" de la gente del Big Data:
Cuando puedas, guardalo todo.
A pesar de su gran popularidad e implantación no todo los tipos de datos funcionan bien en bases de datos relacionales basta con pensar en documentos codificados como XML o en los gráficos que tanto abundan en las redes sociales, a los primeros les convienen más bases de datos como Marklogic y a los segundos como Neo4J.
Además los esquemas de las bases de datos relacionales son muy rígidos mientras que en los entornos No-SQL si se encuentra la flexibilidad que se necesita cuando "exploramos" datos.
Conclusiones
Esta claro que estas 3 "v" son una simplificación, si se quiere, una herramienta de marketing y para mi es cierto, pero me asalta la duda de si merece la pena dejar un concepto como el del Big Data únicamente sujeto a definiciones muy técnicas sólo al alcance de unos pocos.
Aquí tenéis un ejemplo de ese "marketing" en forma de un vídeo presentado en la SAS Analytics Conference en octubre del año pasado, les quedó muy chulo:
Pero como hay que tener en cuenta todos los puntos de vista os dejo un artículo del TDWI bastante contrario al concepto del las 3 "v": Big Data -- Why the three "v" Just Don´t Make Sense
Para Saber Más....
- http://www.businesscomputingworld.co.uk/data-is-exploding-the-3vs-of-big-data/
- http://www.siliconnews.es/2013/02/11/las-cuatro-v-de-big-data/
- http://blog.patternbuilders.com/2013/01/17/big-data-showdown-how-many-vs-do-we-really-need/
- http://www.fiercebigdata.com/story/dump-volume-3-vs-big-data/2013-04-17
- http://multichannel-retailing.com/2012/05/the-3-v-of-big-data/
- http://mashable.com/2012/06/19/big-data-myths/
- http://cloudcomputing.sys-con.com/node/2194841
El Mes del Big Data en Outsourceando
2) Las 3 "V" del Big Data