La industria papelera y maderera tienen un reto en la actualidad, conseguir aprovechar al máximo un bien tan preciado como son los árboles de donde se extrae la pulpa necesaria para la producción de papel, contrachapados, etc. Tiempo atrás os hablé de este proyecto, en el que estoy implicado, en este artículo y ahora empiezan a publicarse los primeros resultados obtenidos en xilanasas extremófilas.
La bioeconomía sostenible es la clave y es uno de los retos del proyecto Woodzymes en el contexto de la madera y la pulpa de papel. Las industrias papeleras y madereras son altamente contaminantes por la generación de subproductos y residuos químicos que se generan. En la actualidad, encontrar nuevos usos a esos productos y cambiar la química tradicional por una química más sostenible, basada en el uso de enzimas, es uno de los objetivos de este proyecto europeo.
Uno de los grandes retos es encontrar enzimas que soporten condiciones extremas de pH alcalino y temperaturas por encima de 80ºC. Un tipo de enzimas de gran interés para este tipo de aplicaciones son las xilanasas. Estas enzimas contribuyen a la degradación de las hemicelulosas facilitando la extracción de la celulosa, ya que participan en la rotura de las interacciones entre celulosa y las ligninas.
El grupo de Estructura y Función de enzimas (del cual formo parte), capitaneado por el Dr. Julio Polaina, ha presentado recientemente un estudio para la detección de xilanasas extremófilas mediante el uso de técnicas bioinformáticas.
En los últimos años el abaratamiento de las técnicas de secuenciación ha dado como resultado inmensas bases de datos con secuencias a las que se les atribuye ciertas características por comparación de secuencias, pero que no han sido caracterizadas bioquímicamente. El factor limitante es poder analizar a nivel de laboratorio esas nuevas secuencias para encontrar candidatos que se adapten a las condiciones requeridas. Sin embargo, un cribado bioinformático previo, puede facilitar la tarea y limitar las secuencias que son analizadas en la bancada del laboratorio.
Un total de 1306 secuencias de la familia GH11 fueron analizadas mediante técnicas bioinformáticas, que permitieron agrupar las secuencias en un gran árbol filogenético, así como obtener la composición estructural de cada una de ellas. Tras comprobar la localización de algunas secuencias provenientes de microorganismos extremófilos se acotaron regiones del árbol que pudiesen contener secuencias correspondientes a organismos termófilos y se escogieron algunas secuencias representativas de estas regiones para su estudio detallado.
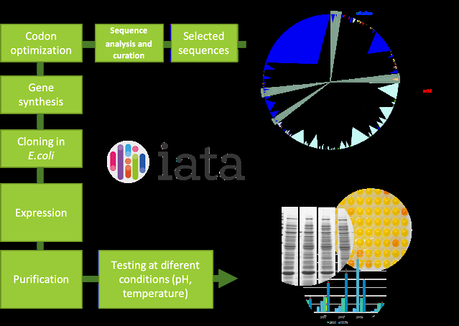
Además, las enzimas que han mostrado mejores resultados se han testado para la digestión de paja de arroz, un residuo para el cual se están buscando usos que eviten su quema y reducir así problemas medioambientales. El tratamiento puede facilitar el compostaje de la paja, así como la obtención de subproductos, como son los xilooligosacáridos, azúcares con carácter prebiótico que han despertado un gran interés en los últimos años por su impacto en la microbiota intestinal.
En la actualidad el grupo sigue trabajando con el cribado de secuencias de bases de datos para encontrar nuevos candidatos que puedan servir para aplicaciones industriales en condiciones extremas y muy pronto se reportarán nuevos resultados de otras familias analizadas.
Os dejamos nuestra última publicación, que además hemos hecho un esfuerzo para que se OpenAcces:

https://biotechnologyforbiofuels.biomedcentral.com/articles/10.1186/s13068-020-01842-5

